架构设计
数据库系统的核心作用在于高效地存储和管理数据,并支持从海量信息中快速检索所需记录。传统的 SQL 关系型数据库在数据规模持续增长的情况下,容易遭遇单机性能瓶颈。目前提升性能的主流做法多依赖垂直扩展增强单机硬件能力,而非水平扩展增加节点以线性扩容。由于其架构限制,关系型数据库在弹性扩展性方面存在障碍,难以充分适应多节点分布式环境。同时为满足 ACID 事务特性,这类系统在支持分布式事务处理时也面临一定的技术挑战。
相比之下,NoSQL 数据库更适用于大规模数据存储和高吞吐、低延迟的应用场景。由于 NoSQL 不受固定数据结构和关系的限制,具有更灵活的扩展能力,并且支持节点的动态扩展,从而更好地适应分布式环境。无论是关系型 SQL 数据库还是 NoSQL 数据库,它们都有一个共同的核心组件存储引擎,这是数据库设计与实现的关键核心部分。
目前数据库存储引擎可以分为两大类,一类是基于内存的 (In-Memory)实现,例如 Redis 和 Memcached 这类的将数据全部存储在内存中;另外一种则是类似于 MySQL 的 InnoDB 和 LevelDB 这种将数据存储在磁盘中。两者都有各自的优势和劣势,基于内存的存储引擎通常存储的数据量较少,但其访问速度往往比基于磁盘的存储引擎快好几个数量级,而基于磁盘的存储引擎访问速度较慢,但存储数据量要比内存引擎多几个数量级。通常内存的价格要比磁盘的贵很多,这也是在选择存储硬件时要考虑的成本问题。
存储引擎的开发者需要权衡读写性能和硬件成本的同时,重点在于如何高效存储数据和检索数据。数据库的存储引擎相当于在操作系统文件系统之上,建立的一套用于数据组织、存储与查询的逻辑管理层,最终实现是依赖于操作系统的文件系统 API 接口的,最终数据是被持久化到磁盘文件中保存,这个就对应着 ACID 中的 Durability 数据持久性。
持久性(Durability)是存储引擎最为至关重要的功能实现,目前很多基于内存版本的 NoSQL 数据库例如 Memcached 和 Redis 在这方面做的就比较差,在 NoSQL 服务器运行过程中突然崩溃断电就会导致数据没有被持久化存储的情况,从而导致数据丢失影响到上层的业务程序。
存储引擎
单机数据库的核心在于其存储引擎,负责实现数据的持久化,并高效地处理数据的写入与读取,是数据库系统性能与可靠性的基础保障。针对这些场景的问题 UrnaDB 采用了基于 Log-Structured Megre Tree 日志结构化文件系统的存储引擎实现,存储引擎会以 Append-Only Log 的方式将所有的数据操作写入到数据文件中。同时 UrnaDB 为了高速查询检索数据记录,存储引擎会将数据记录索引信息全部保存在内存中,从而实现高效快速的查询目标数据记录。这样的设计的好处是能以磁盘最大写入性能进行写入数据,并且还能减少读取磁盘索引所需要的时间,通过一次索引定位来读取数据记录,写入和查询流程图:
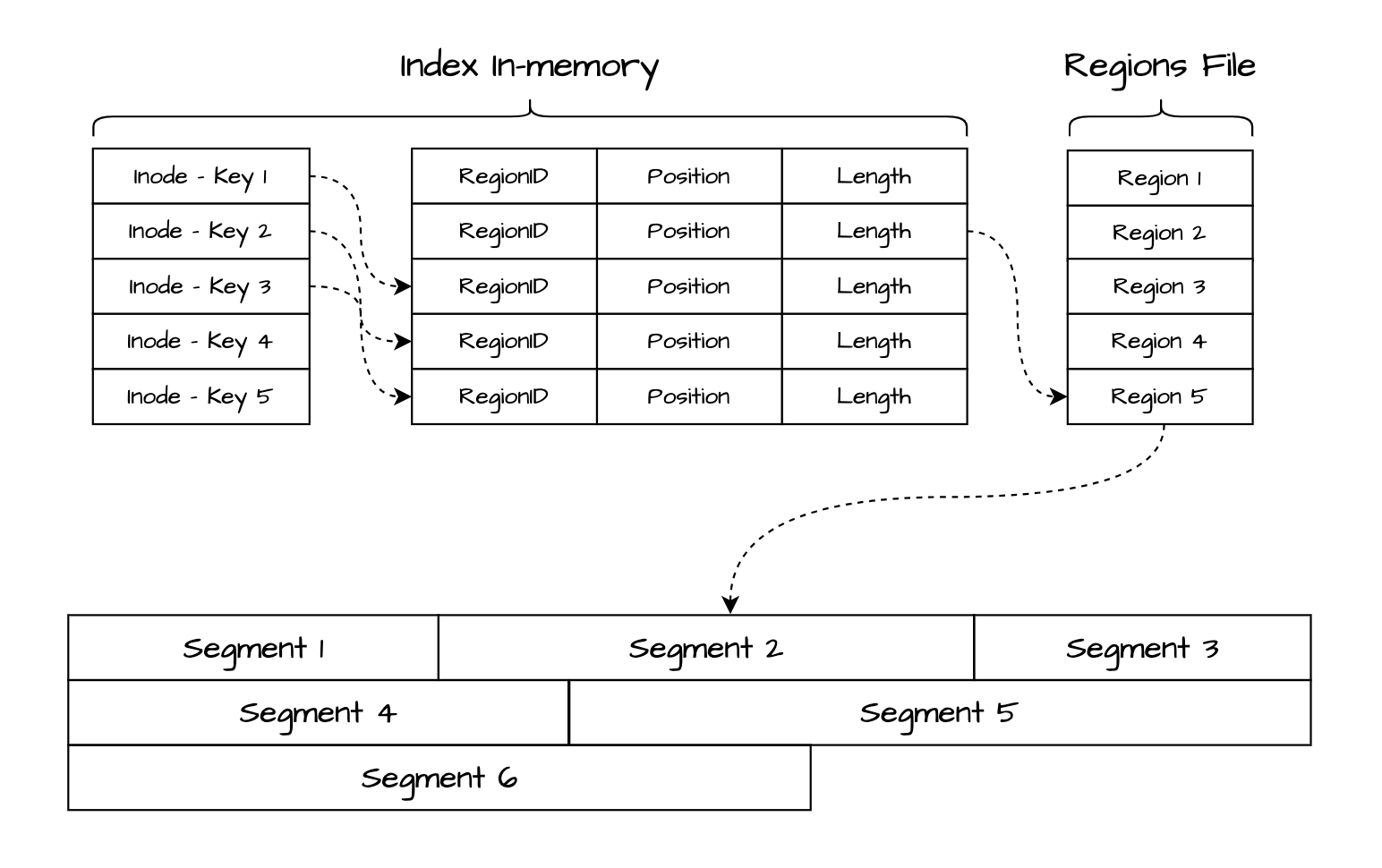
其核心持久化机制基于预写日志 Write-Ahead Logging 简称 WAL ,在对数据执行任何操作前,都会先将操作记录写入 WAL 日志文件。WAL 文件不仅承担持久化的角色,也作为主要的数据存储载体。在数据库进程崩溃后,只需从 WAL 日志中顺序读取各条 Segment 记录,即可高效恢复内存中的索引结构。
在 UrnaDB 中对这些 WAL 数据文件有一个统称为叫 Region 文件,这些文件有单个固定大小限制,当一个数据文件写满之后就会被关闭,会重新创建一个新的 Active 活跃的 Region 文件进行数据记录的进行写入。被关闭的 Region 文件会被视为冷数据文件,随着数据库不间断长时间运行 Region 文件会不断递增逐渐占用磁盘空间。此时数据库进程就需要对旧的 Region 文件执行压缩 Compaction 和定期清理,以降低存储压力并提高查崩溃数据恢复时的启动效率,压缩流程原理图:
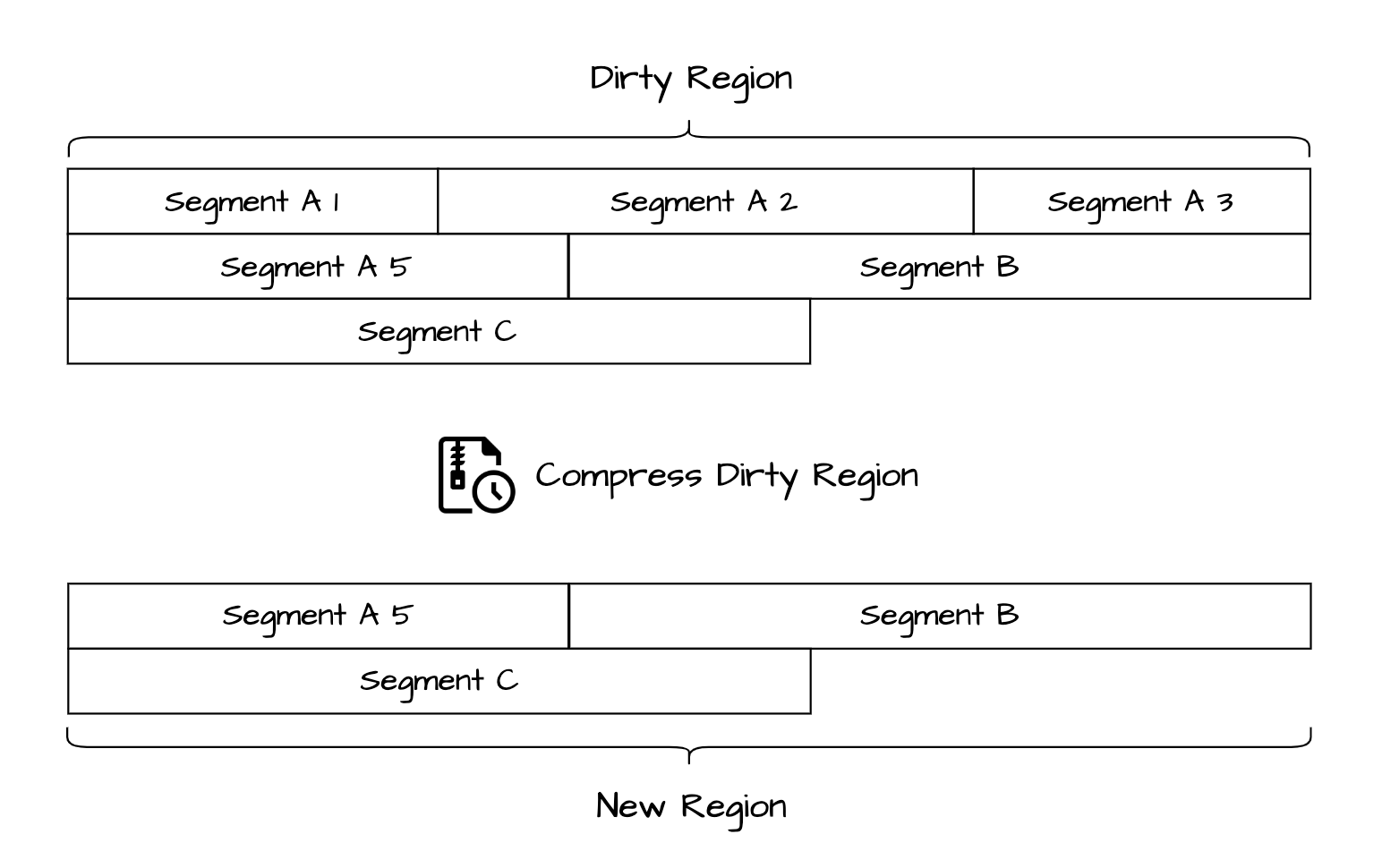
目前工业级的存储系统中,RaikDB 是一个采用类似模型实现的数据库产品,RaikDB 是基于 Amazon Dynamo 论文的设计理念构建而成。其 RaikDB 底层也是采用的顺序写入的日志式存储引擎,并将其命名为 Bitcask 存储模型,以提升写入性能和读写效率。
该模型与 UrnaDB 所采用的存储引擎在设计理念上颇为相似。Bitcask 存储引擎在执行数据压缩 Compaction 时会生成 Hint 文件,其作用是在存储引擎重启时,辅助快速重建内存索引,从而避免每次启动都需全量扫描数据文件,显著提升系统的启动效率。然而 Hint 文件仅在 Compaction 过程中生成,所记录的只是当时内存索引的快照,无法反映实时状态。
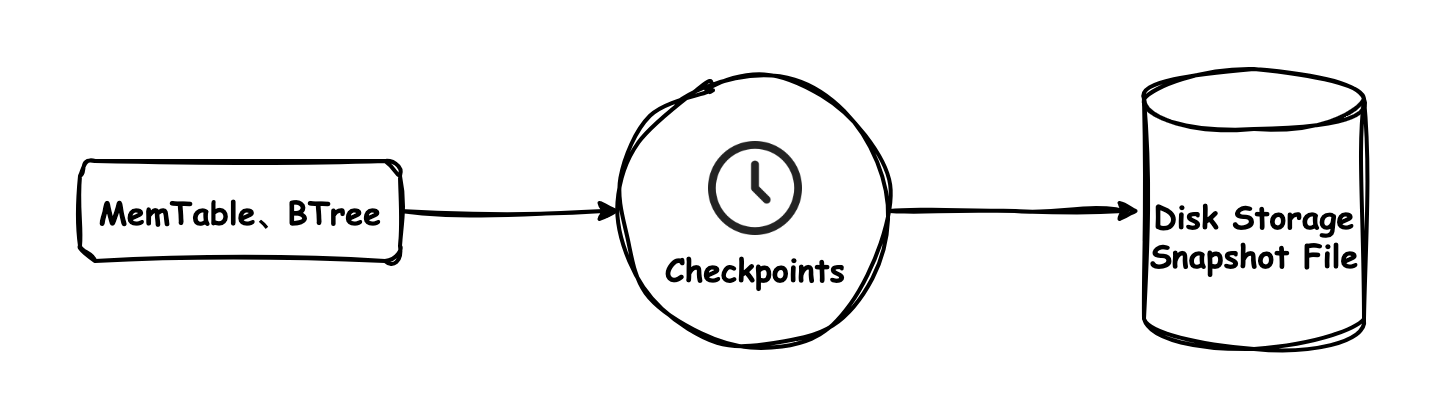
针对这一问题 UrnaDB 在存储引擎中进行了改进,将 Hint 文件机制替换为 Checkpoint 功能,系统会在固定时间间隔内,定期将当前内存索引持久化为 checkpoint 文件写入磁盘。当服务器进程发生异常崩溃,也可通过读取 checkpoint 快照快速恢复内存索引状态。在实际恢复流程中,UrnaDB 会优先加载最近一次的 checkpoint 快照,并从该时间点之后的 Region 文件中继续回放增量数据。通过这种方式,有效提升了系统启动恢复的速度,减少了启动耗时,同时兼顾了数据一致性与运行效率。
服务进程
在此存储引擎设计的基础上,UrnaDB 构建了内置的 HTTP 协议服务器用于数据事物处理,在 UrnaDB 内部有多种数据结构的抽象层,进一步构成了完整的 UrnaDB 产品体系。这些模块构成了一个相互协作、功能完善的 UrnaDB 产品,架构图如下:
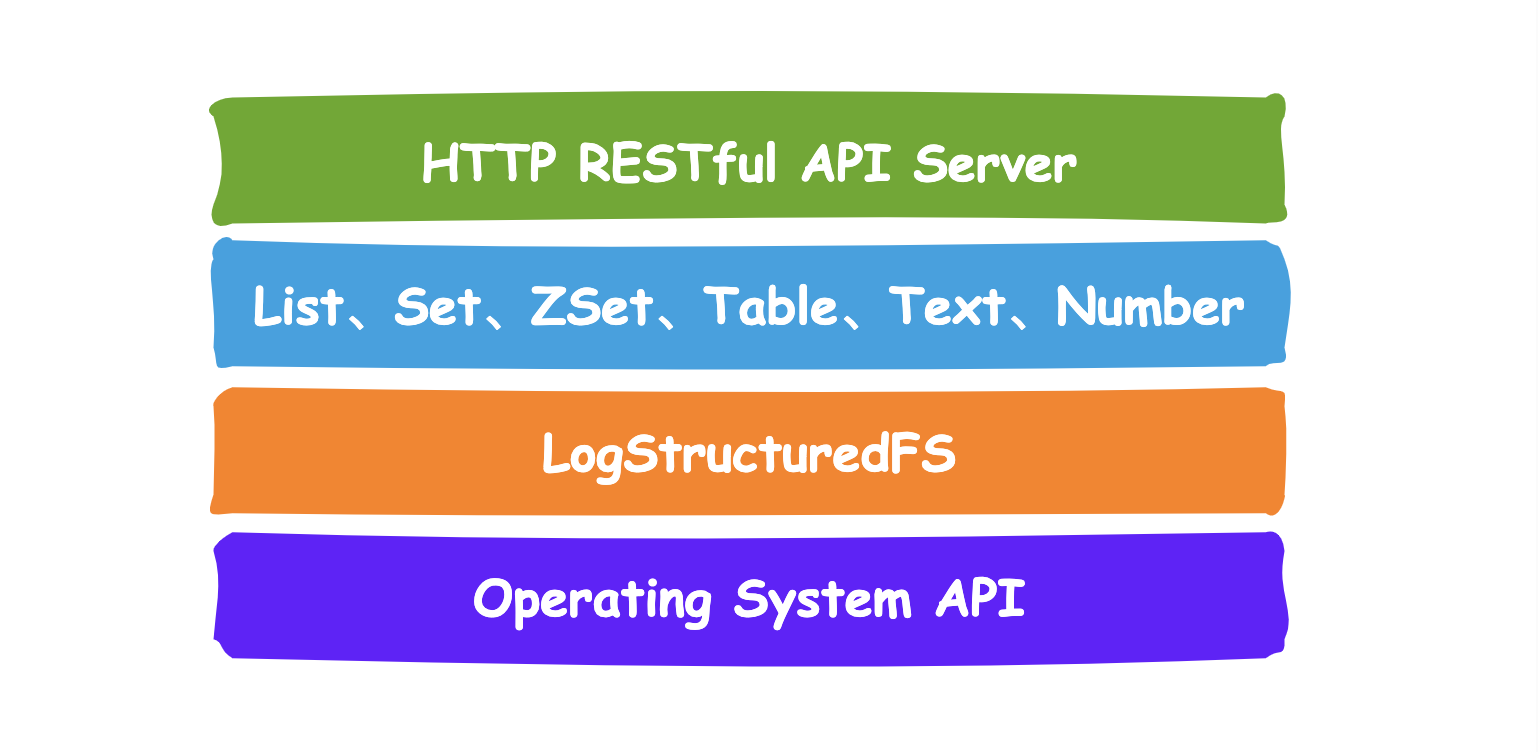
UrnaDB 内部提供了多种数据结构抽象,例如 Table 、Record 、 Variant 、Lock 类型,这些数据类型对应着常见的业务代码所需使用的数据结构。UrnaDB 的服务端对外提供数据交互接口是基于 HTTP 协议的 RESTful API ,只需要通过支持 HTTP 协议客户端软件就可以进行数据操作,这里推荐使用 curl 软件进行数据交互操作,也可以使用官方提供的多语言 SDK 来集成使用,具体如何使用请查阅 SDK 部分的文档内容。
UrnaDB 未来版本将引入更复杂的数据库集群架构,包括分布式存储、多副本机制与高可用性支持,以满足在大规模数据处理、高并发访问以及故障容错方面的实际需求,从而逐步演进为一款支持横向扩展的分布式数据库系统。